Feb 25, 2026

Introducing the Electronics Industry’s First AI Agent with Visual Reasoning
John Williams, Chief Scientist
AI has made extraordinary progress in understanding language.
But in industries like semiconductors, electronics, manufacturing, medical devices, and infrastructure, language represents only a slice of the knowledge.
The most critical technical knowledge is often not written in paragraphs. It is drawn.
It lives in:
Functional block diagrams
Timing charts
Pinout drawings
Performance graphs
Architecture slides
Mechanical specifications
Configuration screenshots
And today, most AI systems simply cannot reason over that content.
At Rapidflare, we’ve developed a Visual Reasoning capability for AI agents that makes diagrams and other image-like technical artifacts first-class knowledge objects, enabling extraction, multi-modal retrieval, and grounded explanation directly from the visual source.
Why Text-Only RAG Falls Short for Electronics Teams
Most enterprise RAG pipelines are built around text. When electronics documents are ingested, PDFs are often flattened, slide decks get reduced to bullet points, and the most important visuals, schematics, block diagrams, timing diagrams, pinouts, and performance curves, are treated as images rather than structured technical data.
As a result, retrieval misses a large share of what engineers and adjacent teams actually need to answer questions accurately. In deep technical domains such as electronics and semiconductors, diagrams aren't decoration, they're the specification. When critical details live in a schematic or engineering drawing, AI must be able to interpret that visual directly. If those artifacts aren’t searchable and retrievable, responses tend to be incomplete, harder to verify, and less useful in real design, debug, and operational workflows.
Applying Visual Reasoning to Electronics Content
With this in mind, Rapidflare has been focused on unlocking the knowledge currently trapped inside enterprise visual content.
Conceptually, Visual Reasoning requires three core capabilities:
Visual Extraction at Ingestion
Multi-Modal Retrieval Across Text and Images
Contextual Multimedia Response Generation
Each represents a significant systems challenge, and together, they define a new category of enterprise AI infrastructure.
Let’s walk through what’s actually involved.
Visual Extraction
Extracting images from enterprise documents may appear straightforward. In reality, technical artifacts require a more deliberate approach to preserve their meaning.
PDFs and slide decks contain far more than embedded pictures. They include:
Raster imagery
Vector-based diagrams
Clipped regions
Transparent overlays
Composite figures built from multiple primitives
Repeated decorative elements and watermarks
Similarly, PowerPoint slides are structured visual compositions, often made up of:
Cropped figures
Masked shapes
Callouts and annotations
Layered transparency
Z-ordered layout hierarchies
Engineers rely on structured visual compositions that convey technical intent. Making this usable for AI requires preserving layout, hierarchy, and relationships between elements, moving beyond raw asset extraction toward structure-aware visual reconstruction that maintains semantic and spatial fidelity.
Multi-Modal Retrieval
Once visuals become first-class knowledge objects, the next challenge is retrieval.
Traditional RAG works by:
Chunking text
Generating embeddings
Performing nearest-neighbor search
Prompting an LLM with retrieved text
This works for prose.
But images require semantic alignment with human technical queries.
Visual Reasoning retrieval incorporates:
Vision-language embeddings
Structured descriptions generated from diagrams
Metadata: product names, hierarchy, document context
Linkage between images and surrounding explanatory text
When someone asks:
“Show me how to configure a test harness for the XYZ-9000.”
The system should retrieve:
The explanatory paragraph
The configuration diagram
The calibration chart
The implementation screenshot
All ranked and fused as part of one coherent answer.
This is where multi-modal retrieval becomes essential.
Text and visuals must exist in the same conceptual search space, or tightly linked ones that can be reasoned over jointly.
Contextual Multimedia Response Generation
Even if you can extract and retrieve visuals, there is a final problem:
Presentation.
Dumping a wall of text followed by a pile of images is not helpful.
A good enterprise response should feel like a domain expert guiding the user:
Introducing the concept
Referencing the right diagram at the right moment
Using visuals to clarify relationships
Grounding explanations in evidence
For example:
“As shown in the block diagram below, the control plane interfaces with the security module through…”
“The timing relationship is illustrated in the waveform figure here…”
“This configuration screen demonstrates the required parameter values…”
The agent must construct a narrative that weaves together reasoning and visual proof, not simply retrieve assets.
This requires orchestration logic, ranking strategies, layout intelligence, and response composition that treats visuals as core knowledge.
Visual Reasoning in Practice: Raspberry Pi Examples
To illustrate why visuals matter for electronics queries, I ingested a public Raspberry Pi corpus, including datasheets, product guides, mechanical drawings, and educational slide decks, and ran a few representative queries across it.
Let’s look at a few examples.
Query 1: How do I set up decoupling capacitors for the RP2040?
My vague question has a deeply technical answer…
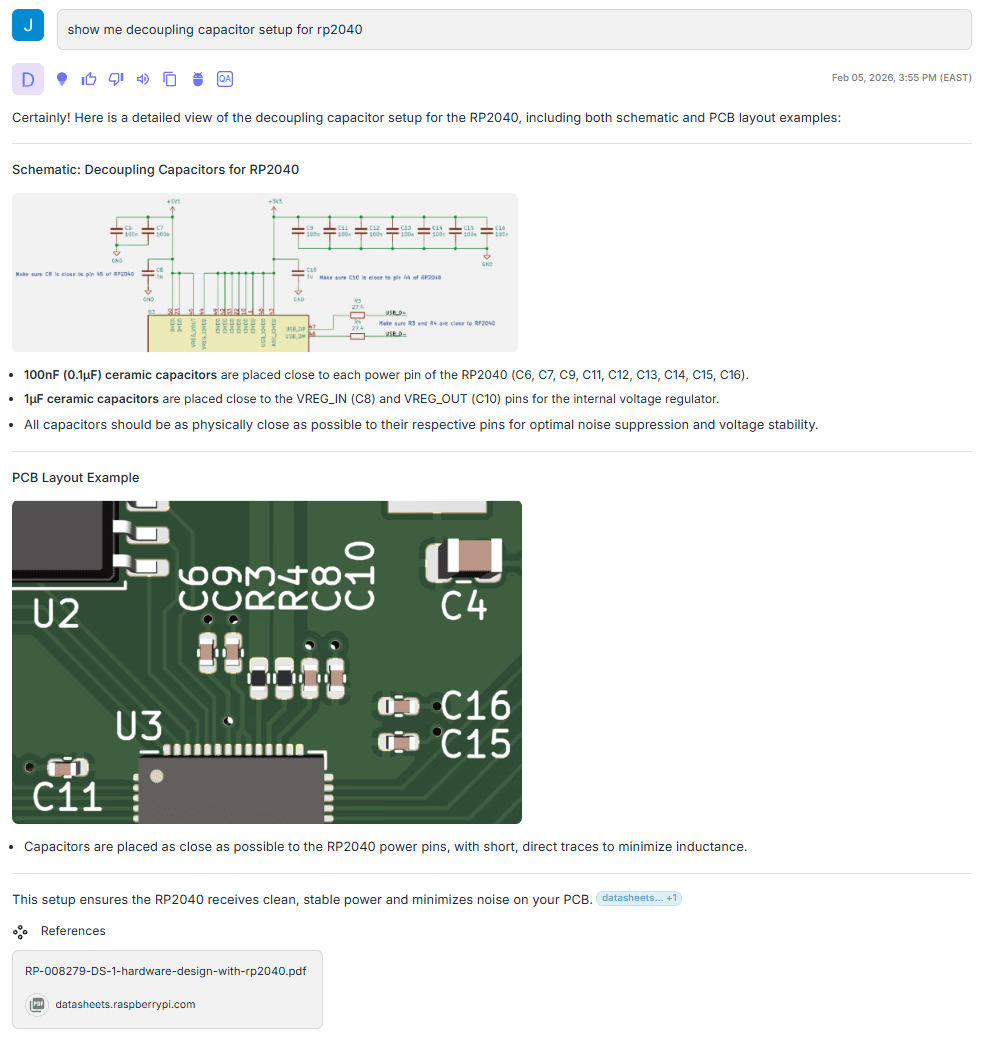
What’s notable here is that the response includes specific values taken directly from the schematic, not from surrounding text. In the referenced source, the capacitor values and annotations appear only in the image, yet the agent extracts them into structured text and returns the original visual as evidence. It also captures design intent embedded in the diagram, such as the note to place the 1 µF capacitors close to the device.
Out of curiosity, I ran the same query through ChatGPT 5.2 to compare the response.

Overall, the answer is directionally correct. But the visuals aren’t tied to the specific schematic context, and it falls back to generic imagery and a best-effort ASCII sketch.
If I’m actually laying out a board, which response would I rather rely on?
Query 2: Imagine I’m new to this and need help with a basic question.
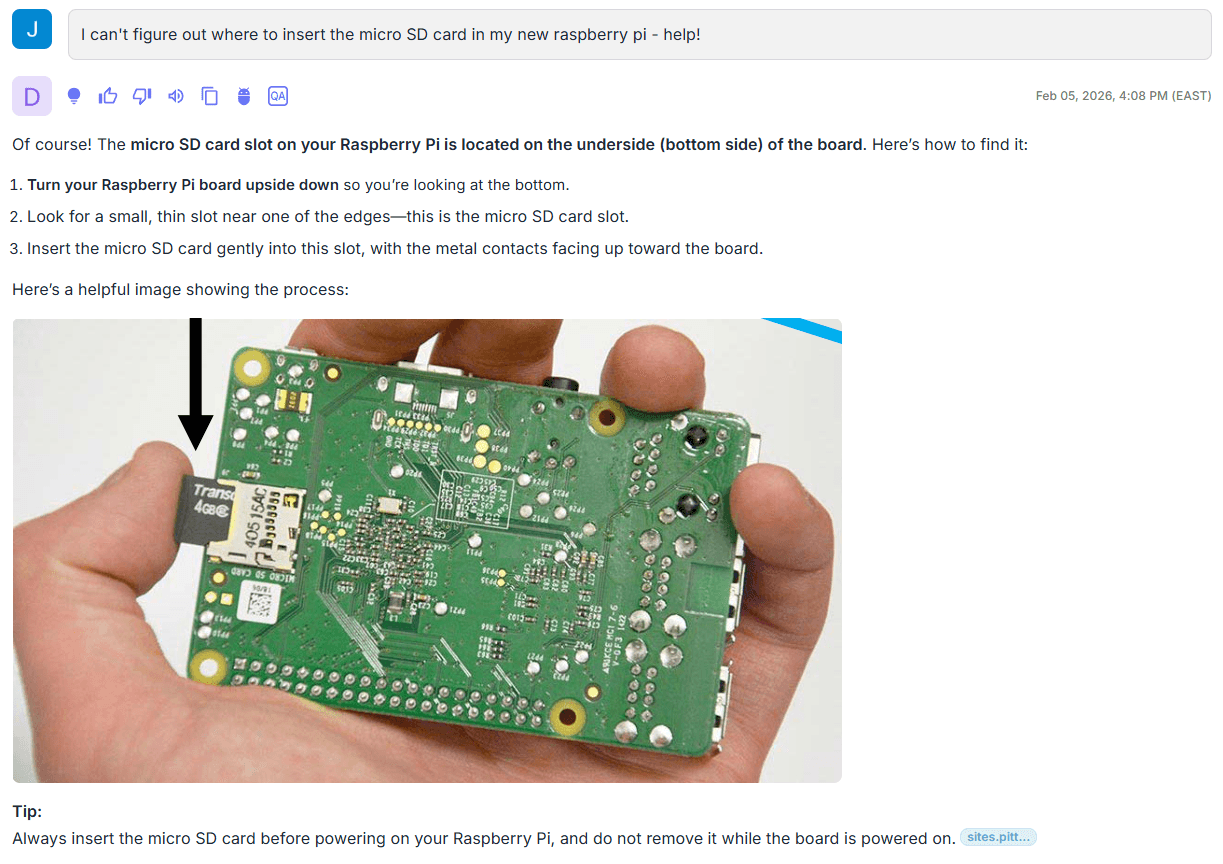
The key difference here is grounding. The image and supporting explanation aren’t coming from general world knowledge or an ad hoc web lookup—they’re retrieved from the specific slide deck we ingested, which is a complete how-to guide for this platform. That’s the practical distinction between a general chatbot and a vertical agent: the response is based on a controlled, curated corpus, so the factual basis is explicit and traceable to the source material.
Query 3: Here, I’m designing a case for my latest Raspberry Pi 4 project, and I need to understand how to mount it…
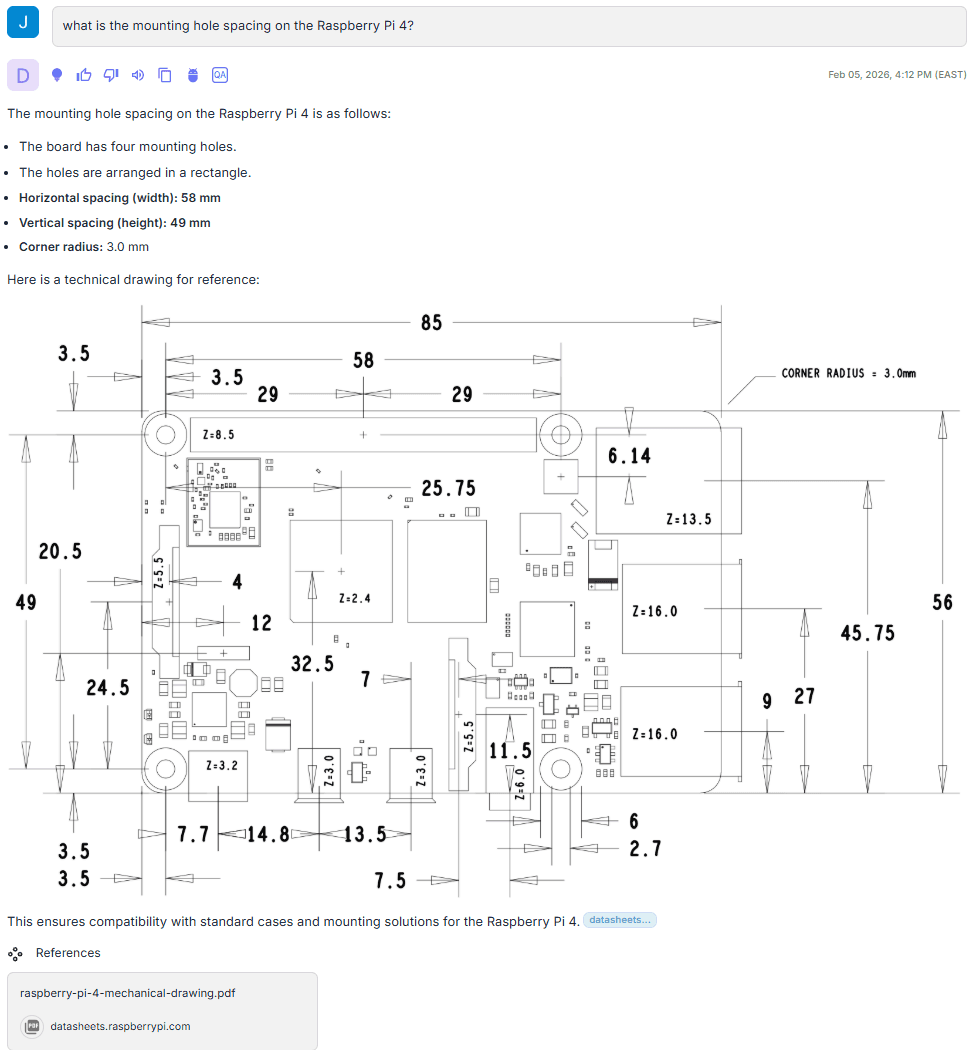
The referenced source here is a mechanical drawing with little to no supporting text. The agent retrieves the correct drawing from the corpus, extracts the required dimensions and constraints directly from the diagram, and includes full references so the result can be verified against the original when needed.
The Practical Payoff: What You Get When Diagrams Become Searchable Knowledge
Bringing visuals into RAG isn’t a small feature. It expands what an enterprise knowledge system can reliably capture and use, especially in electronics.
It improves:
document parsing and visual reconstruction
multi-modal embeddings and figure-level retrieval
linking visuals to surrounding text, entities, and hierarchy
storage and indexing for rich media at scale
response composition that keeps answers traceable to figures
In electronics, the specification is as much visual as it is textual. If an AI system can’t reliably retrieve and reason over schematics, pinouts, timing diagrams, plots, and drawings alongside surrounding text, it will plateau at summaries.
And in engineering contexts, summaries rarely change outcomes.
Because in this domain, a picture really can tell a thousand words, but only if you can ask it the right questions, and verify the answer against the original figure.
Read more

Building Scalable Technical Support for Engineering Communities in Electronics Manufacturing
Vasanth Asokan, Co-founder & CTO
Prush Palanichamy, Co-founder & CRO

Rapidflare Launches Native Discord Integration for Scalable Developer Support
Vasanth Asokan, Co-founder & CTO
Prush Palanichamy, Co-founder & CRO

A Practical Guide to Recall, Precision, and NDCG
Vasanth Asokan, Co-founder & CTO
Prush Palanichamy, Co-founder & CRO
Feb 25, 2026
Introducing the Electronics Industry’s First AI Agent with Visual Reasoning
John Williams, Chief Scientist
AI has made extraordinary progress in understanding language.
But in industries like semiconductors, electronics, manufacturing, medical devices, and infrastructure, language represents only a slice of the knowledge.
The most critical technical knowledge is often not written in paragraphs. It is drawn.
It lives in:
Functional block diagrams
Timing charts
Pinout drawings
Performance graphs
Architecture slides
Mechanical specifications
Configuration screenshots
And today, most AI systems simply cannot reason over that content.
At Rapidflare, we’ve developed a Visual Reasoning capability for AI agents that makes diagrams and other image-like technical artifacts first-class knowledge objects, enabling extraction, multi-modal retrieval, and grounded explanation directly from the visual source.
Why Text-Only RAG Falls Short for Electronics Teams
Most enterprise RAG pipelines are built around text. When electronics documents are ingested, PDFs are often flattened, slide decks get reduced to bullet points, and the most important visuals, schematics, block diagrams, timing diagrams, pinouts, and performance curves, are treated as images rather than structured technical data.
As a result, retrieval misses a large share of what engineers and adjacent teams actually need to answer questions accurately. In deep technical domains such as electronics and semiconductors, diagrams aren't decoration, they're the specification. When critical details live in a schematic or engineering drawing, AI must be able to interpret that visual directly. If those artifacts aren’t searchable and retrievable, responses tend to be incomplete, harder to verify, and less useful in real design, debug, and operational workflows.
Applying Visual Reasoning to Electronics Content
With this in mind, Rapidflare has been focused on unlocking the knowledge currently trapped inside enterprise visual content.
Conceptually, Visual Reasoning requires three core capabilities:
Visual Extraction at Ingestion
Multi-Modal Retrieval Across Text and Images
Contextual Multimedia Response Generation
Each represents a significant systems challenge, and together, they define a new category of enterprise AI infrastructure.
Let’s walk through what’s actually involved.
Visual Extraction
Extracting images from enterprise documents may appear straightforward. In reality, technical artifacts require a more deliberate approach to preserve their meaning.
PDFs and slide decks contain far more than embedded pictures. They include:
Raster imagery
Vector-based diagrams
Clipped regions
Transparent overlays
Composite figures built from multiple primitives
Repeated decorative elements and watermarks
Similarly, PowerPoint slides are structured visual compositions, often made up of:
Cropped figures
Masked shapes
Callouts and annotations
Layered transparency
Z-ordered layout hierarchies
Engineers rely on structured visual compositions that convey technical intent. Making this usable for AI requires preserving layout, hierarchy, and relationships between elements, moving beyond raw asset extraction toward structure-aware visual reconstruction that maintains semantic and spatial fidelity.
Multi-Modal Retrieval
Once visuals become first-class knowledge objects, the next challenge is retrieval.
Traditional RAG works by:
Chunking text
Generating embeddings
Performing nearest-neighbor search
Prompting an LLM with retrieved text
This works for prose.
But images require semantic alignment with human technical queries.
Visual Reasoning retrieval incorporates:
Vision-language embeddings
Structured descriptions generated from diagrams
Metadata: product names, hierarchy, document context
Linkage between images and surrounding explanatory text
When someone asks:
“Show me how to configure a test harness for the XYZ-9000.”
The system should retrieve:
The explanatory paragraph
The configuration diagram
The calibration chart
The implementation screenshot
All ranked and fused as part of one coherent answer.
This is where multi-modal retrieval becomes essential.
Text and visuals must exist in the same conceptual search space, or tightly linked ones that can be reasoned over jointly.
Contextual Multimedia Response Generation
Even if you can extract and retrieve visuals, there is a final problem:
Presentation.
Dumping a wall of text followed by a pile of images is not helpful.
A good enterprise response should feel like a domain expert guiding the user:
Introducing the concept
Referencing the right diagram at the right moment
Using visuals to clarify relationships
Grounding explanations in evidence
For example:
“As shown in the block diagram below, the control plane interfaces with the security module through…”
“The timing relationship is illustrated in the waveform figure here…”
“This configuration screen demonstrates the required parameter values…”
The agent must construct a narrative that weaves together reasoning and visual proof, not simply retrieve assets.
This requires orchestration logic, ranking strategies, layout intelligence, and response composition that treats visuals as core knowledge.
Visual Reasoning in Practice: Raspberry Pi Examples
To illustrate why visuals matter for electronics queries, I ingested a public Raspberry Pi corpus, including datasheets, product guides, mechanical drawings, and educational slide decks, and ran a few representative queries across it.
Let’s look at a few examples.
Query 1: How do I set up decoupling capacitors for the RP2040?
My vague question has a deeply technical answer…
What’s notable here is that the response includes specific values taken directly from the schematic, not from surrounding text. In the referenced source, the capacitor values and annotations appear only in the image, yet the agent extracts them into structured text and returns the original visual as evidence. It also captures design intent embedded in the diagram, such as the note to place the 1 µF capacitors close to the device.
Out of curiosity, I ran the same query through ChatGPT 5.2 to compare the response.
Overall, the answer is directionally correct. But the visuals aren’t tied to the specific schematic context, and it falls back to generic imagery and a best-effort ASCII sketch.
If I’m actually laying out a board, which response would I rather rely on?
Query 2: Imagine I’m new to this and need help with a basic question.
The key difference here is grounding. The image and supporting explanation aren’t coming from general world knowledge or an ad hoc web lookup—they’re retrieved from the specific slide deck we ingested, which is a complete how-to guide for this platform. That’s the practical distinction between a general chatbot and a vertical agent: the response is based on a controlled, curated corpus, so the factual basis is explicit and traceable to the source material.
Query 3: Here, I’m designing a case for my latest Raspberry Pi 4 project, and I need to understand how to mount it…
The referenced source here is a mechanical drawing with little to no supporting text. The agent retrieves the correct drawing from the corpus, extracts the required dimensions and constraints directly from the diagram, and includes full references so the result can be verified against the original when needed.
The Practical Payoff: What You Get When Diagrams Become Searchable Knowledge
Bringing visuals into RAG isn’t a small feature. It expands what an enterprise knowledge system can reliably capture and use, especially in electronics.
It improves:
document parsing and visual reconstruction
multi-modal embeddings and figure-level retrieval
linking visuals to surrounding text, entities, and hierarchy
storage and indexing for rich media at scale
response composition that keeps answers traceable to figures
In electronics, the specification is as much visual as it is textual. If an AI system can’t reliably retrieve and reason over schematics, pinouts, timing diagrams, plots, and drawings alongside surrounding text, it will plateau at summaries.
And in engineering contexts, summaries rarely change outcomes.
Because in this domain, a picture really can tell a thousand words, but only if you can ask it the right questions, and verify the answer against the original figure.
Read more
Building Scalable Technical Support for Engineering Communities in Electronics Manufacturing
Vasanth Asokan, Co-founder & CTO
Prush Palanichamy, Co-founder & CRO
Rapidflare Launches Native Discord Integration for Scalable Developer Support
Vasanth Asokan, Co-founder & CTO
Prush Palanichamy, Co-founder & CRO
AI has made extraordinary progress in understanding language.
But in industries like semiconductors, electronics, manufacturing, medical devices, and infrastructure, language represents only a slice of the knowledge.
The most critical technical knowledge is often not written in paragraphs. It is drawn.
It lives in:
Functional block diagrams
Timing charts
Pinout drawings
Performance graphs
Architecture slides
Mechanical specifications
Configuration screenshots
And today, most AI systems simply cannot reason over that content.
At Rapidflare, we’ve developed a Visual Reasoning capability for AI agents that makes diagrams and other image-like technical artifacts first-class knowledge objects, enabling extraction, multi-modal retrieval, and grounded explanation directly from the visual source.
Why Text-Only RAG Falls Short for Electronics Teams
Most enterprise RAG pipelines are built around text. When electronics documents are ingested, PDFs are often flattened, slide decks get reduced to bullet points, and the most important visuals, schematics, block diagrams, timing diagrams, pinouts, and performance curves, are treated as images rather than structured technical data.
As a result, retrieval misses a large share of what engineers and adjacent teams actually need to answer questions accurately. In deep technical domains such as electronics and semiconductors, diagrams aren't decoration, they're the specification. When critical details live in a schematic or engineering drawing, AI must be able to interpret that visual directly. If those artifacts aren’t searchable and retrievable, responses tend to be incomplete, harder to verify, and less useful in real design, debug, and operational workflows.
Applying Visual Reasoning to Electronics Content
With this in mind, Rapidflare has been focused on unlocking the knowledge currently trapped inside enterprise visual content.
Conceptually, Visual Reasoning requires three core capabilities:
Visual Extraction at Ingestion
Multi-Modal Retrieval Across Text and Images
Contextual Multimedia Response Generation
Each represents a significant systems challenge, and together, they define a new category of enterprise AI infrastructure.
Let’s walk through what’s actually involved.
Visual Extraction
Extracting images from enterprise documents may appear straightforward. In reality, technical artifacts require a more deliberate approach to preserve their meaning.
PDFs and slide decks contain far more than embedded pictures. They include:
Raster imagery
Vector-based diagrams
Clipped regions
Transparent overlays
Composite figures built from multiple primitives
Repeated decorative elements and watermarks
Similarly, PowerPoint slides are structured visual compositions, often made up of:
Cropped figures
Masked shapes
Callouts and annotations
Layered transparency
Z-ordered layout hierarchies
Engineers rely on structured visual compositions that convey technical intent. Making this usable for AI requires preserving layout, hierarchy, and relationships between elements, moving beyond raw asset extraction toward structure-aware visual reconstruction that maintains semantic and spatial fidelity.
Multi-Modal Retrieval
Once visuals become first-class knowledge objects, the next challenge is retrieval.
Traditional RAG works by:
Chunking text
Generating embeddings
Performing nearest-neighbor search
Prompting an LLM with retrieved text
This works for prose.
But images require semantic alignment with human technical queries.
Visual Reasoning retrieval incorporates:
Vision-language embeddings
Structured descriptions generated from diagrams
Metadata: product names, hierarchy, document context
Linkage between images and surrounding explanatory text
When someone asks:
“Show me how to configure a test harness for the XYZ-9000.”
The system should retrieve:
The explanatory paragraph
The configuration diagram
The calibration chart
The implementation screenshot
All ranked and fused as part of one coherent answer.
This is where multi-modal retrieval becomes essential.
Text and visuals must exist in the same conceptual search space, or tightly linked ones that can be reasoned over jointly.
Contextual Multimedia Response Generation
Even if you can extract and retrieve visuals, there is a final problem:
Presentation.
Dumping a wall of text followed by a pile of images is not helpful.
A good enterprise response should feel like a domain expert guiding the user:
Introducing the concept
Referencing the right diagram at the right moment
Using visuals to clarify relationships
Grounding explanations in evidence
For example:
“As shown in the block diagram below, the control plane interfaces with the security module through…”
“The timing relationship is illustrated in the waveform figure here…”
“This configuration screen demonstrates the required parameter values…”
The agent must construct a narrative that weaves together reasoning and visual proof, not simply retrieve assets.
This requires orchestration logic, ranking strategies, layout intelligence, and response composition that treats visuals as core knowledge.
Visual Reasoning in Practice: Raspberry Pi Examples
To illustrate why visuals matter for electronics queries, I ingested a public Raspberry Pi corpus, including datasheets, product guides, mechanical drawings, and educational slide decks, and ran a few representative queries across it.
Let’s look at a few examples.
Query 1: How do I set up decoupling capacitors for the RP2040?
My vague question has a deeply technical answer…
What’s notable here is that the response includes specific values taken directly from the schematic, not from surrounding text. In the referenced source, the capacitor values and annotations appear only in the image, yet the agent extracts them into structured text and returns the original visual as evidence. It also captures design intent embedded in the diagram, such as the note to place the 1 µF capacitors close to the device.
Out of curiosity, I ran the same query through ChatGPT 5.2 to compare the response.
Overall, the answer is directionally correct. But the visuals aren’t tied to the specific schematic context, and it falls back to generic imagery and a best-effort ASCII sketch.
If I’m actually laying out a board, which response would I rather rely on?
Query 2: Imagine I’m new to this and need help with a basic question.
The key difference here is grounding. The image and supporting explanation aren’t coming from general world knowledge or an ad hoc web lookup—they’re retrieved from the specific slide deck we ingested, which is a complete how-to guide for this platform. That’s the practical distinction between a general chatbot and a vertical agent: the response is based on a controlled, curated corpus, so the factual basis is explicit and traceable to the source material.
Query 3: Here, I’m designing a case for my latest Raspberry Pi 4 project, and I need to understand how to mount it…
The referenced source here is a mechanical drawing with little to no supporting text. The agent retrieves the correct drawing from the corpus, extracts the required dimensions and constraints directly from the diagram, and includes full references so the result can be verified against the original when needed.
The Practical Payoff: What You Get When Diagrams Become Searchable Knowledge
Bringing visuals into RAG isn’t a small feature. It expands what an enterprise knowledge system can reliably capture and use, especially in electronics.
It improves:
document parsing and visual reconstruction
multi-modal embeddings and figure-level retrieval
linking visuals to surrounding text, entities, and hierarchy
storage and indexing for rich media at scale
response composition that keeps answers traceable to figures
In electronics, the specification is as much visual as it is textual. If an AI system can’t reliably retrieve and reason over schematics, pinouts, timing diagrams, plots, and drawings alongside surrounding text, it will plateau at summaries.
And in engineering contexts, summaries rarely change outcomes.
Because in this domain, a picture really can tell a thousand words, but only if you can ask it the right questions, and verify the answer against the original figure.
Read more
Building Scalable Technical Support for Engineering Communities in Electronics Manufacturing
Vasanth Asokan, Co-founder & CTO
Prush Palanichamy, Co-founder & CRO
Rapidflare Launches Native Discord Integration for Scalable Developer Support
Vasanth Asokan, Co-founder & CTO
Prush Palanichamy, Co-founder & CRO
Supercharged Sales Enablement
Rapidflare AI Agents for Next Generation Sales


Copyright 2025 @ Rapidflare, Inc.
Supercharged Sales Enablement
Rapidflare AI Agents for Next Generation Sales
Copyright 2025 @ Rapidflare, Inc.
Supercharged Sales Enablement
Rapidflare AI Agents for Next Generation Sales
Copyright 2025 @ Rapidflare, Inc.
