Nov 3, 2025

A Practical Guide to Recall, Precision, and NDCG
Dipkumar Patel, Founding Engineer
Introduction
Retrieval-Augmented Generation (RAG) is revolutionizing how Large Language Models (LLMs) access and use information. By grounding models in domain specific data from authoritative sources, RAG systems deliver more accurate and context-aware answers.
But a RAG system is only as strong as its retrieval layer. Suboptimal retrieval performance results in low recall, poor precision, and incoherent ranking signals that degrade overall relevance and user trust.
This guide outlines a step-by-step approach to optimizing RAG retrieval performance through targeted improvements in recall, precision, and NDCG (Normalized Discounted Cumulative Gain). It’s designed to help AI researchers, engineers, and developers build more accurate and efficient retrieval pipelines.
The Basics of RAG Retrieval
Retrieval is the foundation of any Retrieval-Augmented Generation (RAG) system. There are two main retrieval methods, each offering unique strengths.
Vector Search (Semantic Search)
Transforms text into numerical embeddings that capture semantic meaning and relationships. It retrieves conceptually related results, even without keyword overlap.
Example: A query for “machine learning frameworks” retrieves documents about PyTorch and TensorFlow.
Full-Text Search (Keyword Search)
Matches exact phrases and keywords. It’s fast and efficient for literal queries but lacks contextual understanding.
Example: It finds “machine learning frameworks” only if the phrase appears verbatim.

Pro Tip: Use hybrid search (vector + keyword) to combine the contextual power of vector retrieval with the speed and precision of keyword matching—ideal for most RAG pipelines.
Key Metrics for RAG Retrieval Performance
Before optimizing, measure your retrieval performance using three key metrics:
Recall
Did we retrieve all relevant content?
If 85 of 100 relevant documents are found, recall = 85%. Low recall means missing key data.
Precision
How much irrelevant data did we avoid?
If 70 of 100 retrieved results are relevant, precision = 70%. Low precision introduces noise that reduces LLM quality.
NDCG (Normalized Discounted Cumulative Gain)
Are the most relevant results ranked highest?
High NDCG ensures your system ranks top-quality documents first—essential for LLMs with limited context windows.
Optimization Priorities:
Maximize Recall – capture all relevant data.
Improve Precision – reduce retrieval noise.
Optimize NDCG – enhance ranking quality.
Step 1: Maximize Recall
Strong recall ensures complete information coverage for your RAG retrieval pipeline.
Techniques:
Query Expansion: Add synonyms and related terms (e.g., “Transformer models” → “BERT,” “attention mechanisms”).
Hybrid Search: Combine vector and keyword results (e.g., reciprocal rank fusion).
Fine-Tuned Embeddings: Train on domain-specific data (finance, legal, healthcare) for improved recall.
Smart Chunking: Segment text into overlapping chunks (250–500 tokens) for granular coverage.
Benchmark chunk size and overlap for best results.
Step 2: Increase Precision
After retrieving broadly, refine for relevance and context alignment.
Techniques:
Re-Rankers: Use transformer-based reranking models (e.g., BERT, Cohere Rerank API) to reorder top results.
Metadata Filtering: Exclude irrelevant or outdated documents using attributes such as date or source.
Thresholding: Apply similarity cutoffs (e.g., cosine > 0.5) to remove weak matches.
Higher precision means cleaner context and more accurate RAG generation.
Step 3: Optimize NDCG (Ranking Quality)
Good recall and precision mean little without effective ranking.
Techniques:
Advanced Reranking: Reorder top candidates by contextual relevance.
User Feedback Loops: Use click and dwell-time data to promote high-value results.
Context-Aware Retrieval: Include key entities or prior concepts from conversation history—without appending full chat logs.
Measure Improvement: Label a small dataset with relevance scores and track NDCG@5 or NDCG@10.
Aim for a 5–10 % boost per iteration.
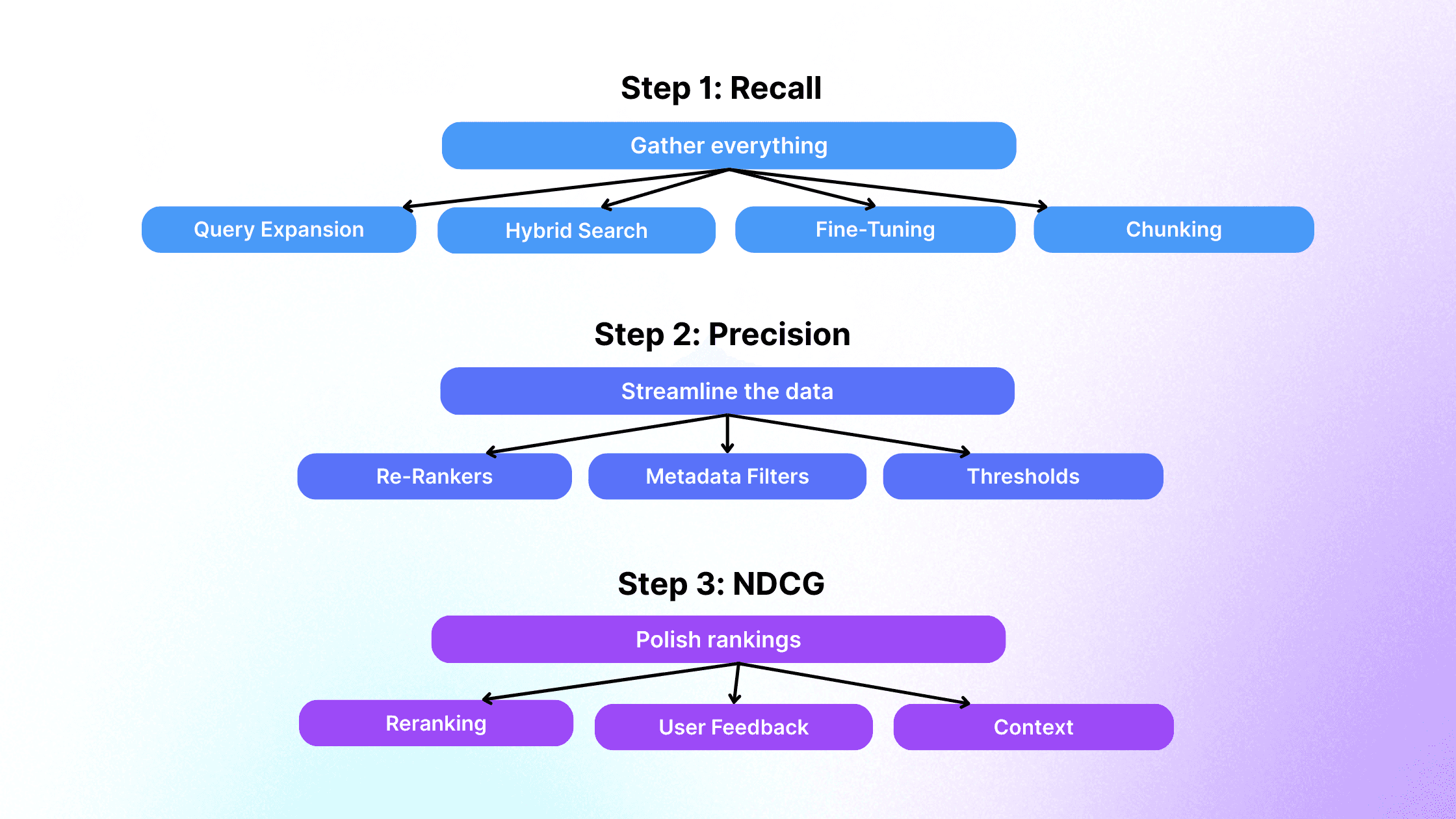
Building the Retrieval Flywheel
Effective RAG retrieval optimization is iterative:
Maximize Recall – broaden coverage.
Boost Precision – refine relevance.
Enhance NDCG – improve ranking stability.
Continuously experiment with chunk sizes, thresholds, and rerankers. Measure, iterate, and evolve your retrieval pipeline for higher accuracy and efficiency.
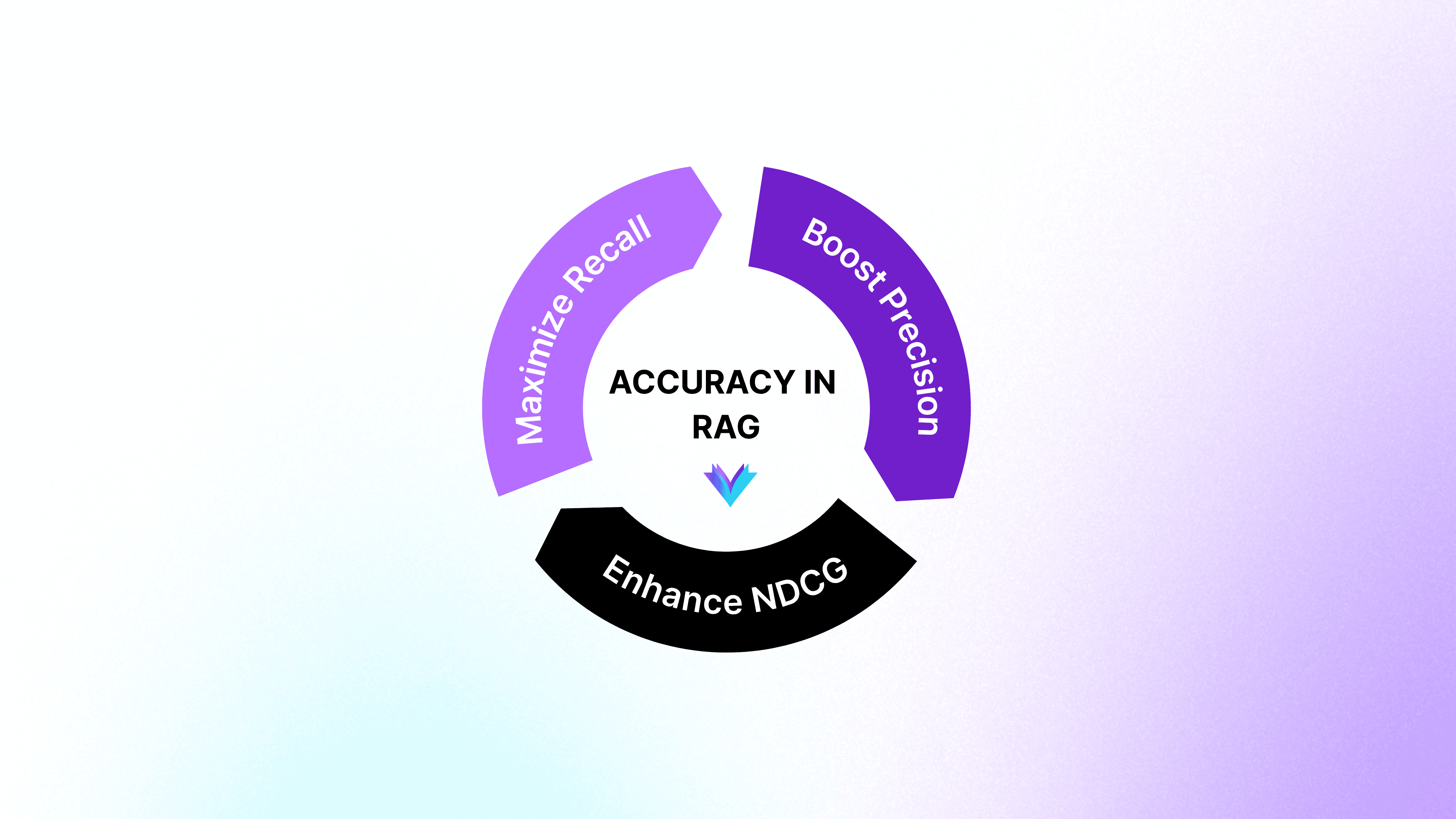
RAG Retrieval Optimization Cheat Sheet

Conclusion
Optimizing retrieval in RAG systems ensures your LLM has the most relevant, high-quality grounding data.
By continuously improving recall, precision, and NDCG, you build a smarter, faster, and more reliable RAG pipeline that evolves with your data and domain.
Read more
Rapidflare and Rolling Wireless Partner to Transform Technical Support for Connected Automotive and IoT Products
Vasanth Asokan, Co-founder & CTO
Prush Palanichamy, Co-founder & CRO

The Question Before the Answer: How We Built LLM-Powered Autocomplete
Vasanth Asokan, Co-founder & CTO
Prush Palanichamy, Co-founder & CRO

Introducing the Electronics Industry’s First AI Agent with Visual Reasoning
Vasanth Asokan, Co-founder & CTO
Prush Palanichamy, Co-founder & CRO
Nov 3, 2025
A Practical Guide to Recall, Precision, and NDCG
Dipkumar Patel, Founding Engineer
Introduction
Retrieval-Augmented Generation (RAG) is revolutionizing how Large Language Models (LLMs) access and use information. By grounding models in domain specific data from authoritative sources, RAG systems deliver more accurate and context-aware answers.
But a RAG system is only as strong as its retrieval layer. Suboptimal retrieval performance results in low recall, poor precision, and incoherent ranking signals that degrade overall relevance and user trust.
This guide outlines a step-by-step approach to optimizing RAG retrieval performance through targeted improvements in recall, precision, and NDCG (Normalized Discounted Cumulative Gain). It’s designed to help AI researchers, engineers, and developers build more accurate and efficient retrieval pipelines.
The Basics of RAG Retrieval
Retrieval is the foundation of any Retrieval-Augmented Generation (RAG) system. There are two main retrieval methods, each offering unique strengths.
Vector Search (Semantic Search)
Transforms text into numerical embeddings that capture semantic meaning and relationships. It retrieves conceptually related results, even without keyword overlap.
Example: A query for “machine learning frameworks” retrieves documents about PyTorch and TensorFlow.
Full-Text Search (Keyword Search)
Matches exact phrases and keywords. It’s fast and efficient for literal queries but lacks contextual understanding.
Example: It finds “machine learning frameworks” only if the phrase appears verbatim.
Pro Tip: Use hybrid search (vector + keyword) to combine the contextual power of vector retrieval with the speed and precision of keyword matching—ideal for most RAG pipelines.
Key Metrics for RAG Retrieval Performance
Before optimizing, measure your retrieval performance using three key metrics:
Recall
Did we retrieve all relevant content?
If 85 of 100 relevant documents are found, recall = 85%. Low recall means missing key data.
Precision
How much irrelevant data did we avoid?
If 70 of 100 retrieved results are relevant, precision = 70%. Low precision introduces noise that reduces LLM quality.
NDCG (Normalized Discounted Cumulative Gain)
Are the most relevant results ranked highest?
High NDCG ensures your system ranks top-quality documents first—essential for LLMs with limited context windows.
Optimization Priorities:
Maximize Recall – capture all relevant data.
Improve Precision – reduce retrieval noise.
Optimize NDCG – enhance ranking quality.
Step 1: Maximize Recall
Strong recall ensures complete information coverage for your RAG retrieval pipeline.
Techniques:
Query Expansion: Add synonyms and related terms (e.g., “Transformer models” → “BERT,” “attention mechanisms”).
Hybrid Search: Combine vector and keyword results (e.g., reciprocal rank fusion).
Fine-Tuned Embeddings: Train on domain-specific data (finance, legal, healthcare) for improved recall.
Smart Chunking: Segment text into overlapping chunks (250–500 tokens) for granular coverage.
Benchmark chunk size and overlap for best results.
Step 2: Increase Precision
After retrieving broadly, refine for relevance and context alignment.
Techniques:
Re-Rankers: Use transformer-based reranking models (e.g., BERT, Cohere Rerank API) to reorder top results.
Metadata Filtering: Exclude irrelevant or outdated documents using attributes such as date or source.
Thresholding: Apply similarity cutoffs (e.g., cosine > 0.5) to remove weak matches.
Higher precision means cleaner context and more accurate RAG generation.
Step 3: Optimize NDCG (Ranking Quality)
Good recall and precision mean little without effective ranking.
Techniques:
Advanced Reranking: Reorder top candidates by contextual relevance.
User Feedback Loops: Use click and dwell-time data to promote high-value results.
Context-Aware Retrieval: Include key entities or prior concepts from conversation history—without appending full chat logs.
Measure Improvement: Label a small dataset with relevance scores and track NDCG@5 or NDCG@10.
Aim for a 5–10 % boost per iteration.
Building the Retrieval Flywheel
Effective RAG retrieval optimization is iterative:
Maximize Recall – broaden coverage.
Boost Precision – refine relevance.
Enhance NDCG – improve ranking stability.
Continuously experiment with chunk sizes, thresholds, and rerankers. Measure, iterate, and evolve your retrieval pipeline for higher accuracy and efficiency.
RAG Retrieval Optimization Cheat Sheet
Conclusion
Optimizing retrieval in RAG systems ensures your LLM has the most relevant, high-quality grounding data.
By continuously improving recall, precision, and NDCG, you build a smarter, faster, and more reliable RAG pipeline that evolves with your data and domain.
Read more
Rapidflare and Rolling Wireless Partner to Transform Technical Support for Connected Automotive and IoT Products
Vasanth Asokan, Co-founder & CTO
Prush Palanichamy, Co-founder & CRO
The Question Before the Answer: How We Built LLM-Powered Autocomplete
Vasanth Asokan, Co-founder & CTO
Prush Palanichamy, Co-founder & CRO
Introduction
Retrieval-Augmented Generation (RAG) is revolutionizing how Large Language Models (LLMs) access and use information. By grounding models in domain specific data from authoritative sources, RAG systems deliver more accurate and context-aware answers.
But a RAG system is only as strong as its retrieval layer. Suboptimal retrieval performance results in low recall, poor precision, and incoherent ranking signals that degrade overall relevance and user trust.
This guide outlines a step-by-step approach to optimizing RAG retrieval performance through targeted improvements in recall, precision, and NDCG (Normalized Discounted Cumulative Gain). It’s designed to help AI researchers, engineers, and developers build more accurate and efficient retrieval pipelines.
The Basics of RAG Retrieval
Retrieval is the foundation of any Retrieval-Augmented Generation (RAG) system. There are two main retrieval methods, each offering unique strengths.
Vector Search (Semantic Search)
Transforms text into numerical embeddings that capture semantic meaning and relationships. It retrieves conceptually related results, even without keyword overlap.
Example: A query for “machine learning frameworks” retrieves documents about PyTorch and TensorFlow.
Full-Text Search (Keyword Search)
Matches exact phrases and keywords. It’s fast and efficient for literal queries but lacks contextual understanding.
Example: It finds “machine learning frameworks” only if the phrase appears verbatim.
Pro Tip: Use hybrid search (vector + keyword) to combine the contextual power of vector retrieval with the speed and precision of keyword matching—ideal for most RAG pipelines.
Key Metrics for RAG Retrieval Performance
Before optimizing, measure your retrieval performance using three key metrics:
Recall
Did we retrieve all relevant content?
If 85 of 100 relevant documents are found, recall = 85%. Low recall means missing key data.
Precision
How much irrelevant data did we avoid?
If 70 of 100 retrieved results are relevant, precision = 70%. Low precision introduces noise that reduces LLM quality.
NDCG (Normalized Discounted Cumulative Gain)
Are the most relevant results ranked highest?
High NDCG ensures your system ranks top-quality documents first—essential for LLMs with limited context windows.
Optimization Priorities:
Maximize Recall – capture all relevant data.
Improve Precision – reduce retrieval noise.
Optimize NDCG – enhance ranking quality.
Step 1: Maximize Recall
Strong recall ensures complete information coverage for your RAG retrieval pipeline.
Techniques:
Query Expansion: Add synonyms and related terms (e.g., “Transformer models” → “BERT,” “attention mechanisms”).
Hybrid Search: Combine vector and keyword results (e.g., reciprocal rank fusion).
Fine-Tuned Embeddings: Train on domain-specific data (finance, legal, healthcare) for improved recall.
Smart Chunking: Segment text into overlapping chunks (250–500 tokens) for granular coverage.
Benchmark chunk size and overlap for best results.
Step 2: Increase Precision
After retrieving broadly, refine for relevance and context alignment.
Techniques:
Re-Rankers: Use transformer-based reranking models (e.g., BERT, Cohere Rerank API) to reorder top results.
Metadata Filtering: Exclude irrelevant or outdated documents using attributes such as date or source.
Thresholding: Apply similarity cutoffs (e.g., cosine > 0.5) to remove weak matches.
Higher precision means cleaner context and more accurate RAG generation.
Step 3: Optimize NDCG (Ranking Quality)
Good recall and precision mean little without effective ranking.
Techniques:
Advanced Reranking: Reorder top candidates by contextual relevance.
User Feedback Loops: Use click and dwell-time data to promote high-value results.
Context-Aware Retrieval: Include key entities or prior concepts from conversation history—without appending full chat logs.
Measure Improvement: Label a small dataset with relevance scores and track NDCG@5 or NDCG@10.
Aim for a 5–10 % boost per iteration.
Building the Retrieval Flywheel
Effective RAG retrieval optimization is iterative:
Maximize Recall – broaden coverage.
Boost Precision – refine relevance.
Enhance NDCG – improve ranking stability.
Continuously experiment with chunk sizes, thresholds, and rerankers. Measure, iterate, and evolve your retrieval pipeline for higher accuracy and efficiency.
RAG Retrieval Optimization Cheat Sheet
Conclusion
Optimizing retrieval in RAG systems ensures your LLM has the most relevant, high-quality grounding data.
By continuously improving recall, precision, and NDCG, you build a smarter, faster, and more reliable RAG pipeline that evolves with your data and domain.
Read more
Rapidflare and Rolling Wireless Partner to Transform Technical Support for Connected Automotive and IoT Products
Vasanth Asokan, Co-founder & CTO
Prush Palanichamy, Co-founder & CRO
The Question Before the Answer: How We Built LLM-Powered Autocomplete
Vasanth Asokan, Co-founder & CTO
Prush Palanichamy, Co-founder & CRO
Supercharged Sales Enablement
Rapidflare AI Agents for Next Generation Sales


Copyright 2025 @ Rapidflare, Inc.
Supercharged Sales Enablement
Rapidflare AI Agents for Next Generation Sales
Copyright 2025 @ Rapidflare, Inc.
Supercharged Sales Enablement
Rapidflare AI Agents for Next Generation Sales
Copyright 2025 @ Rapidflare, Inc.
